Seguro que te ha pasado: le haces una pregunta crucial a tu IA de confianza y, aunque su respuesta suena brillante y convincente, te queda esa pequeña espina de duda en el pecho. ¿Es real lo que me está diciendo o es solo una «alucinación» muy bien escrita?
Esa incertidumbre es, hoy por hoy, el mayor muro entre nosotros y el verdadero potencial de la tecnología. Por suerte, la industria ha decidido que ya es hora de derribarlo.
FACTS Benchmark Suite es una ambiciosa iniciativa de Google y Kaggle que busca algo que parecía imposible: medir sistemáticamente la honestidad de la inteligencia artificial.
No es solo un test técnico; es el primer paso real para que dejes de cuestionar cada dato y empieces, por fin, a confiar.
Los cuatro pilares de la certeza: ¿Cómo se mide la verdad?
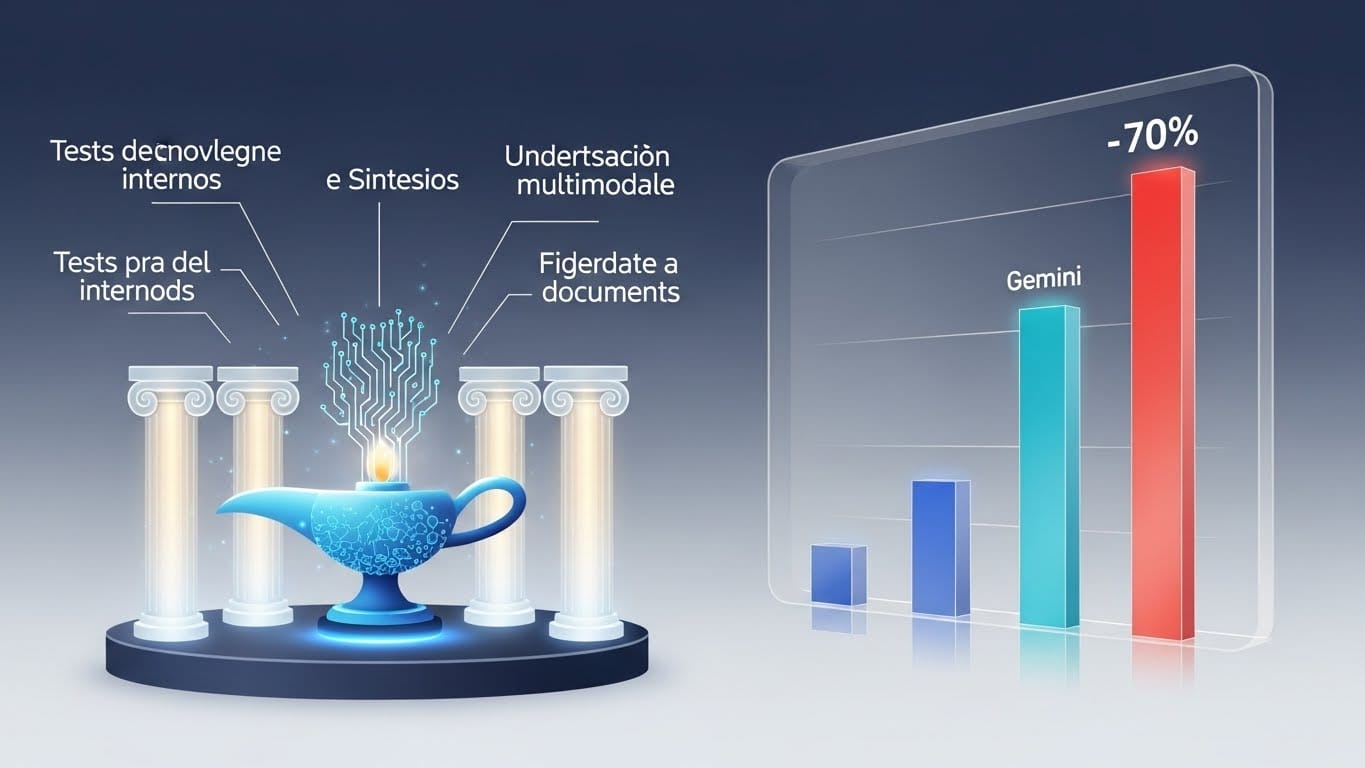
Para que puedas confiar plenamente en una respuesta, la IA debe demostrar que domina varios frentes a la vez. El equipo de FACTS ha diseñado un «examen de alto rendimiento» con 3,513 desafíos específicos para mapear sus límites.
El primer gran pilar es el benchmark paramétrico. Aquí, la IA debe responder basándose solo en su «memoria» interna, sin ayuda externa. ¿Es capaz de recordar un dato muy específico de Wikipedia o se inventará el nombre de una serie antigua?
El segundo pilar es el benchmark de búsqueda, y aquí es donde el nivel sube de verdad. No basta con que la IA sepa usar un buscador; debe razonar.
Se le piden tareas complejas que exigen conectar varios hechos dispersos en la web para dar una única respuesta coherente. Es la prueba definitiva para saber si la IA sabe sintetizar información útil para ti o si se pierde entre miles de resultados.
Visión y contexto: el reto de entender lo que la IA ve
El tercer pilar de este ecosistema es el benchmark multimodal. Aquí es donde las cosas se ponen realmente difíciles para los modelos, porque no solo se trata de «ver», sino de interpretar y conectar esa imagen con el conocimiento real del mundo.
Imagina que le muestras la foto de un primate poco común y le pides su género científico; la IA debe ser capaz de reconocer los rasgos visuales y cruzarlos con su base de datos interna sin cometer errores que te confundan.
Pero hay un cuarto elemento que quizás te resulte aún más útil en tu día a día: el Grounding Benchmark v2. Esta prueba mide la capacidad del modelo para «no salirse del guion».
Cuando le entregas un documento largo y le pides un resumen, este benchmark evalúa que la IA se base estrictamente en el texto que tú le has proporcionado.
Es el freno de mano contra la invención, asegurando que la respuesta esté anclada a tus datos y no a su propia imaginación.
El veredicto de los datos: Gemini 3 pro y la carrera por el 70%
Tras someter a 15 de los modelos más avanzados a estas pruebas, los resultados son reveladores: Gemini 3 Pro se ha posicionado como el líder indiscutible con una puntuación global del 68,8%.
Lo más impresionante es el salto que ha dado frente a su versión anterior, reduciendo los errores en un 55% en tareas de búsqueda y un 35% en conocimientos generales.
Sin embargo, hay un dato que debería hacernos reflexionar: a pesar de estos avances, ningún modelo ha logrado romper la barrera del 70%.
Esto nos indica que, aunque la tecnología está mejorando a pasos agigantados —como demuestra también su éxito en el test SimpleQA Verified, donde Gemini 3 Pro alcanzó un 72,1% de precisión—, todavía queda un camino emocionante por recorrer.
Estamos ante una «cura de humildad» para la industria que, lejos de ser negativa, establece una hoja de ruta clara para que las herramientas que usas a diario sean cada vez más fiables.
El techo de cristal de la facticidad: ¿por qué la IA aún reprueba?
Es posible que ese 68,8% te parezca una nota insuficiente si la comparas con un examen escolar, pero en el mundo de la inteligencia artificial, es un hito de transparencia. ¿Por qué no llegamos aun al sobresaliente? El mayor obstáculo actual es la integración de «sentidos».
En el benchmark multimodal, las puntuaciones fueron las más bajas de todo el estudio, lo que revela que a las máquinas les cuesta horrores hacer algo que tú haces de forma natural: ver un objeto, identificarlo y relacionarlo con su contexto sin titubear.
Este «techo de cristal» nos recuerda que la IA no es una entidad omnisciente, sino un sistema en constante aprendizaje.
El equipo de FACTS define este margen como un «espacio para el progreso», una hoja de ruta que garantiza que la investigación no se detendrá hasta que la tasa de alucinación sea mínima.
Para ti, esto significa que, aunque la IA es hoy una aliada más poderosa que nunca, todavía es vital que mantengas tu espíritu crítico, especialmente en temas de alta sensibilidad donde la precisión lo es todo.
El futuro se escribe con datos, no con promesas
Al final del día, el FACTS Benchmark Suite es más que una tabla de posiciones; es un compromiso de honestidad. La colaboración con Kaggle marca un cambio de era: ya no nos basta con que una IA sea elocuente o creativa, ahora exigimos que sea veraz.
El liderazgo de Gemini 3 Pro es una excelente noticia, pero la verdadera victoria es que hoy tenemos una vara de medir real para evitar los sesgos y la desinformación.
La próxima vez que uses una IA, recuerda que hay todo un equipo trabajando para que el «no lo sé» sea una opción más valiosa que una mentira bien adornada. Estamos construyendo una inteligencia con la que, por fin, podrás hablar con total seguridad.